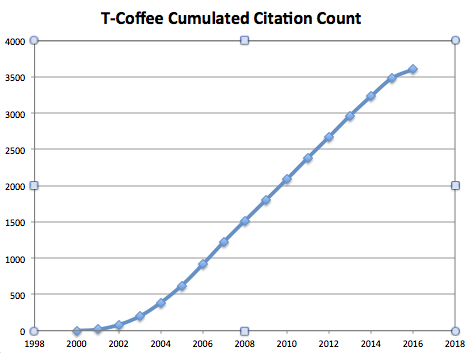
The last time I looked it up - an hour ago - our original T-Coffee paper had 3602 citations on scopus. I used to think this was a lot, until Nature ran this story on the Kilimandjaro height of scientific publications. The most cited paper is at 300.000... It gives all these numbers some kind of perspective I guess. I am not a huge fan of modern metrics and I usually find difficult to stay awake in front of Hollywood blockbusters ranked by their box-office gross product, like Batman 25 or Superman 2^6, yet I tend to think popularity and quality are simply not correlated as opposed to being mutually exclusive. This rigidly self-enforced open mindedness allows me to consider my highly and poorly cited papers as equally good - or bad when I am not in the right mood…
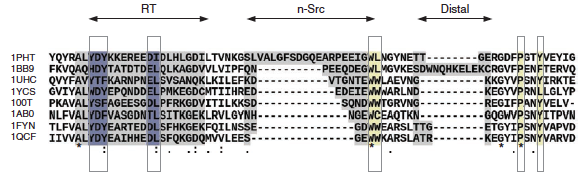
How you get that kind of citation level for a method paper is not a straight road, in fact it is not a road at all, more of an accident and a fall or anything related to bumping your head in the dark and waking up in hospital. I thought it might be interesting for younger scientists to get an idea on how these things happen and why no time should be wasted at planning them. The truth is that even a story I should know perfectly, like T-Coffee, turns out to be riddled with speculative patches when tracing back onto how things seem to have really happened.For those who have no clue what T-Coffee does, il is a multiple sequence aligner. It means that it takes a bunch of biological sequences - typically proteins - that have evolved from a common ancestor by accumulating mutations, insertions and deletions. Aligning them involves putting in the same column - aligning - the amino acids (represented as letters) that were already present in the common ancestor, as shown in the picture below. The rest of the positions - those not homologous across all the sequences - get padded with null symbols (-) we call gaps - just like the ‘mind the gap’ in London’s tube. Said this way it looks pretty simple, but it turns out that it is one of these computational problems that cannot be solved exactly - period. Computer people call them NP-Complete. These problems are good fun because as far as solutions are concerned, anything goes, just like Niagara fall stunt contraptions. And trust me, over these last 20 years, anything has gone... It is hard to think of any optimisation algorithm - no matter how crazy it may sound - that has not been thrown in the face of the multiple alignment problem. From Simulated Annealing to Genetic Algorithm, Tabu Search and probably many more I have never heard of. T-Coffee is one of them. Why do we care so much about these multiple sequence alignments? Because they can be a useful starting point to infer most things that matter in Biology, from evolutionary trees down to enzyme active sites analysis. This explains why methods describing them are among the most cited - not only in Biology but in Science in general.
T-Coffee started with another multiple aligner named Dialign, or to be more precise an earlier paper by Burkhard Morgenstern, in PNAS, about gap penalty free alignments. It came out just when I was finishing my PhD at the European Bioinformatics Institute. I really liked Burkhard’s paper. I was especially impressed with the concept he named overlapping weights. I don’t want to go into anything technical here, but these weights were smart because they allowed all the sequences to talk together while being aligned, for a tiny extra computation cost. I liked that and spent a few unsuccessful nights re-implementing the concept in a quick-and-dirty way. I failed and moved on with my main project of the time which was to get a genetic algorithm computing alignments through in-silico sexual activity (aka genetic algorithm). But the idea - I mean the Dialign idea - lingered on and four years later it was still in my mind when I eventually implemented T-Coffee, and combined Burkhard’s weights with the ClustalW progressive algorithm. Said this way it looks pretty straightforward, but things are a bit more complicated and my take on this has been a major source of - friendly - disagreement with Burkhart who insisted many times that the two approaches are very different.
If CRISPERism was to become a trend, this would be the exact opposite. Two scientists arguing to establish their non-paternity of a method - “we stole your ideas!” “No you did not and we will resist any attempt of you saying you did!”. Half kidding... the aligners world is very civilized. Of course, Burkhart has a few good points, especially when going down to the fine grain details, but it does not change anything to the fact that I had the overlapping weights in mind when designing T-Coffee. I find this a great showcase of how alternative realities can coexist - even (especially?) in science. And no, I am not attacking Led Zep. I want to believe they were acting in good faith.Another thing that makes T-Coffee a very average research project is that it did not start as a shinny clinking idea that I would have had in my bathtub, or, worse, while writing a grant. Quite the opposite: T-Coffee was originally a bug. At the time I was evaluating alignments by comparing them with other alignments and I somehow messed up the file names and ended up running unintended comparisons. Readouts were very good, the kind of very good I find very suspicious as a PI. With such results it was either instant fame or else. Taking care of the else factor resulted in the usual degraded performance and shattered dreams of fame and Science Magazine covers. I remember coming home that night on my red mopped - registered with diplomatic plates thanks to the EMBL international statute - and sadly chewing on my midnight kebbab. Scientific failure is never healthy - neither is success by the way, too much sulfites. On the following day I did the right thing. I insist on this because I do not recall doing the right thing very often in my life, but that day I did. I carefully traced back and figured out why it had looked so good for a while. It turned out that the suspiciously informative comparisons had been made against collections of pairwise alignments. It’s like taking all the sequences, aligning them two by two, and checking on the agreement against a full multiple sequence alignment. This is the precise moment T-Coffee was born and it has not changed much since then.
At the time it was not T-Coffee. It was called something obscure. When searching for a name, I could not resist a libertarian quick fix by coming out with the silliest acronyme I could fit. It became “Consistency Objective Function For alignmEnt Evaluation” the E was a bit of a cheat - I know and I don’t apologize. I then met in Greece, at the ISMB, with Des Higgins, my PhD supervisor. I would usually come to Des with crazy ideas of neural networks coupled with genetic algorithms. Des took advantage of these discussions to teach me everything I needed to learn as a future PhD supervisor: “Do it!”, “Could be...”, “I don’t know”, “Have you looked it up in the literature?”. But on that special occasion his face lit up and he immediately liked it. Even-though he may have forgotten about this, his encouragements on that specific day remained the driving force of what was to become a lonnnng and mostly unsuccessful project. This was the summer of 1997, T-Coffee was already a year old.
I had to finish my PhD in a rush because EMBL likes its PhD program to look efficient - as does the EU - and I wrote a big fuzzy paper that read more like the leftover of a not so smart but much luckier Galois. As one should have expected - I did not - it was smoothly rejected by NAR and eventually published in Bioinformatics - the journal formerly known as CABIOS. I like to think that the paper acceptance had nothing to do with me harassing Barbara Cox - the secretary, or Chris Sander - the editor - who where my office neighbours. Then again there are many other good things I like to think about myself. In any case, the COFFEE paper that has now about a 130 citations is the ancestor of T-Coffee as acknowledged by 130 gourmet bioinformaticians. It contains most of the original ideas about the new ways of evaluating alignments we had come out with. If we all have a paper we are secretly more fond of - a one that we find more personal - then COFFEE would be mine.
The time had come to turn this idea into a usable aligner, which COFFEE was not. COFFEE was a way of evaluating alignments, we call this an objective function, but it did not tell you how to build the alignment. For this, I had been using a genetic algorithm, that was marginally faster that a return journey between Oxford and Cambridge after British Railway privatisation - in case all you know about British trains comes from Sherlock Holmes, well, time have changed... I really had to get something faster, and scavenging the ClustalW algorithm turned out to be the best option - sorry Julie. I spent my last months at the EBI coding that stuff. This was intense enough so that most people I knew in Cambridge thought I was already gone, or dead, or something. A comment by a friend, on the day I was leaving England to defend my PhD in France, perfectly captured the whole process of wrapping up a PhD: “I wonder if this patch of hair on your forehead will ever grow back”. It did not.
The new T-Coffee was a highly sophisticated piece of code - euphemism for terrible - and I used most of my time in Switzerland in the group of Philipp Bucher to recode it. Philipp - and his funding agency - had been under the impression I would come working for the Prosite database. Over the few months I spent there, not only did I not do anything on Prosite - except messing up a few hyperlinks - but I also cannibalised Philipps attention to give suggestions on T-Coffee. For instance, he is the one who came out with the idea of combining local and global alignments. Why is he not on the paper? The only reason I can think of is because the project took three more years, three more labs, and three more countries to finalize. By that time, I had entirely lost track of who had done what to whom and vice versa (what? lab book? Are we supposed to have one of these?). I regret it but find some consolation in the idea that no one will be dropped out of a nobel because of this.
I left Switzerland for England with a first version of T-Coffee that was happily allocating the whole amount of RAM memory available in the UK at that time. This original version of T-Coffee is kept in a secret vault and considered a national security hazard. I will say no more. Fortunately, I then joined the group of Jaap Heringa in Willy Taylor’s program at the NIMRC. There I got myself in the best possible environment to clean up T-Coffee. It’s a long time I have not visited Mill Hill and I am not sure what is left of it - I know that Paul Nurse’s Cricky ambitions have shuffled things there quite a bit - but at the time the MRC was a place to drink a lot of coffee in the afternoon, beer on site in the local pub, talk a lot and be a scientist the way you had dreamt of becoming a scientist - in an absurdly under-assuming way, entirely captured by Michael Green and his monkey-based protein models. It took a good more year, and there we were, Des, Jaap and myself, fiddling with the first manuscript draft. We had it very clear: give me Science Magazine or give me death.
As we all know, the cool thing with these big journals is that you get fast rejection and move on, but if you don’t get a quick rejection, things get exciting. So we got excited, but for the wrong reason. Indeed I had left the MRC the day after submission and had taken a new appointment in France, in the lab of Jean Michel Claverie. Two months after submission we still had not received any rejection letter and I was beginning to browse Champagne millesimes. Unfortunately, the rejection letter had simply enjoyed a wet British summer, resting on my former desk...Yes, you know who you are if you read this, but thanks anyway for giving us so much hope and expectation over an entire summer...
This letter has long been lost and is not part of the file that I have posted here, neither is the Nature rejection. I seem to remember we tried Nature but I honestly could not find any trace of any failed attempt… Then again I do not have enough storage space for all my rejection letters... Our next best step was to be PNAS. And there things got hairy. It is a long time I have not submitted to PNAS, but in these days it was horrendous. You had to print things on american sized paper - a rare commodity in Europe. Then you had to use an esoteric formula to estimate your word counts while measuring figure sizes and margins, using some ratio of transcendental numbers for the final correction. Nothing was electronic and a typical submission would take you a couple of days while wasting paper worth about an acre of rainforest in the dry season.
But finally it was gone. It stayed there a couple of month until early December when I received this cryptic fax from PNAS.

That was just before Xmas and not the best time of the year to start running complex analysis but this was my chance, my break, my day, my year! I jumped into it with all the energy you have when below 30. I think we did a pretty good job at answering the reviews but Xmas is a bad time and the editor almost immediately rejected our paper while inviting us to re-submit. Unfortunately I have lost that one as well. We did so on the first days of February and the paper was smoothly and permanently rejected by PNAS early March. Looking back with my current experience, I think we should have fought a bit harder… Still I got mad about it, decided to dump everything in some archive and forget about it. It is Jaap who managed to convince me to keep it alive and go for JMB. Janet Thornton handled the manuscript and that was the smoothest ride any of my paper ever had. And that was it. T-Coffee was published. It came out on the 8th of September 2000.
For most projects, that’s where things stop, and then you move on. The 192 hours of teaching French assistant professors owe to the state quickly got all this research nonsense out of my mind. The next big milestone came two weeks later. It was an email with “T-Coffee” as subject and “Lipman, David (NIH/NLM/NCBI) [E]” in the “from” line. Yes the MAN himself. He was sending me a very polite e-mail asking things about T-Coffee. David Lipman was asking me questions about T-Coffee! I have to stress this one more time: Mr Blast was interested in half roasted T-Coffee. I have had other epiphanies but this one was intense enough to fry the hairpiece I had received as a PhD viva gift. We exchanged a bit more and David eventually invited me to visit the NCBI for a couple of weeks. I would need another long blog entry to to describe the visit of the holy temple of bioinformatics.
Among the many things that happened while visiting the NCBI, one took place that entirely changed the T-Coffee citation fate. Eugene Koonin. Most young scientists looking for Eugene papers probably think that this must be a very common name among Russian biologists. They probably assume an army of Eugene Koonin-s. Well I have some news for you. There is only one and yes he has done everything and the rest and a bit more. And it gets even more confusing if you consider that he is also a pretty normal human being - that is as far as bioinformaticians go of course... Visiting Eugene was too good to be true but it got even better when I realized he had the same Indy Silicon Graphic workstation on which I was developing T-Coffee (nice blue boxes). This matters because T-Coffee was - poorly - written in C and was only stable on this precise machine. I installed it on his machine, and ran T-Coffee on a couple of datasets. Eugene liked the alignments. I then bumped into David in the stairs who asked me how were things. I mentioned Eugene liking T-Coffee alignments. “He liked them!?” there was a mixture of suspicion, excitement and admiration in his tone.
Then I went back to my teaching in France and gradually forgot about all this. It took a good year for the first citation to come. It was Nick Grishin. Then Eugene and Aravind - the two most famous domain hunters - took on using T-Coffee on a regular basis, and everything started. If Koonin and Aravind are using an aligner, who would be crazy enough to use another one? Biology, especially wet lab, is pretty much a cooking exercise. You take a recipe and follow it line by line. If at line 5 the Chef says “Take T-Coffee”, then you take T-Coffee, not because you would blindly follow anyone, but because you know the Chef is good - you have eaten there food before. One thing to know about methods papers is that they always start slowly and it often takes more than three years to get the first 30 citations. This is the reason why big journals don’t care about us - we don’t contribute much to the Holly Impact Factor. But once a method gets going, it can really rock, so be patient.
Well, I guess the time has come to wrap up this little piece with some element for the edification of young scientists. Well let me think... First don’t eat too much kebab or at least stay away from the variety loaded with french fries, secondly insist on getting fireproof hairpieces, thirdly make sure influential people know about your work - even if they eat kebab with you. We may like it or not but things in biology are very relative - social networks matter as much a gels do. Yes, there are people you trust and those you don’t. This is probably even more true now that automated metrics compilation systems can be fooled by anyone. With fake papers, fake reviewers, fake results, the only thing that’s left to us is reputation as supported by those with whom we get drunk. The rest is just damp octopus, squid and squib.