It is always a bit tricky to do some story telling about the development of an IT software like Nextflow. If you have no idea what Nextflow is, do not feel alarmed. Most people in the real world have no clue either. To make it short, Nextflow is a pipeline language developed to deal with genomics data. Nextflow helps processing very large datasets in a reproducible way. What kind of datasets? Well let us say you have a cancer patient whose genome has been sequenced in order to look for cancer driving mutations. You will need a pipeline to analyze this data. This is where Nextflow comes handy. More and more people use it to implement the pipelines they need. They also rely on Nextflow to run the computation on a big central machine, on the cloud or even on a laptop. Today, I am not really going to explain how Nextflow works as this is all explained in the original paper. I would rather tell you a funnier story: how it all started...
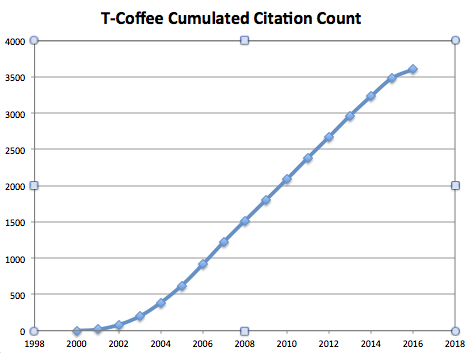
For a start, I must make it clear that I did not write a single line of code in Nextflow. Such a non-contribution was an entirely new experience to me. As far as PIs in my generation go, I am still pretty hands on and I take a lot of pleasure in re-implementing my lab’s algorithm, slowly growing T-Coffee, my favorite piece of code, into some kind of convoluted monster.
But this did not happen with Nextflow, which taught me one of the most important lessons in my career: trust those who know better than you. Doing so is not simple. Many years ago, when I started as a PI, I did what I occasionally see junior PIs doing: I started drawing arrows between boxes, hand-waving on the obvious simplicity of the connectors. Not that simple, I am afraid. Reality shows that in a research lab, there is blood dripping from almost every arrow drawn between each and every box of a scientific diagram. There will always be blood, but the only way I know of to stop the hemoragia is to not pretend knowing what you do not know… Not the most valued skill these days I am afraid...
But back to the beginning… I am not really an IT guy and my first contact with virtual machines happened with some odd back-up solutions that were made possible on PC, about 20 years ago. I got fascinated with the fact that once dumped the right way, your machine could be Frankesteined back into its exact original state - you did not even need thunder. I had spent my PhD working on genetic algorithms. These things were running forever and always crashing at the worst possible time, and no matter how hard you tried to dump the status every once in a while, the resuming was always tedious with random seeding pushing repeatability out of bound. So the notion that your entire machine could be snapped-shot and resumed anywhere felt like a miracle. Then I moved to the CRG. This was an interesting period when computation was suddenly becoming, once more, an issue in biology.
When writing “once again”, I should probably clarify what I have in mind... During most of the 90s, universities kept buying gigantic equipment, possibly because this looked like a respectable way to burn money and make a statement that you were investing hard cash in research. Hardware companies like Intel and HP thought this was indeed a great idea. Also, having the biggest computer in the universe would put you in the spotlight for a couple of weeks. To put it simply, CPU was scaling well with money and ticked all the boxes needed for a report. This is probably genuinely true in some CPU intensive data simulation domains, like meteorology or aerodynamics, but at the time this was not so clear in genomics. So when you had the university knocking on your door and asking if you could do great science with their big machines, you had to say “yes we can!”, and then you were left to scratch your head. The thing is that in these days, the computational complexity of most genomics heuristic algorithms was so bad that having machines 10 times bigger did not change things much. At the human scale, waiting 10 billion years, or 100 billion years is pretty much the same thing. Memory requirements were even worse. What kind of problem can you have that eternal life would not solve!!? Well, memory allocation is one...
Of course, I am talking mostly about the usual suspects like building trees or computing big multiple sequence alignments. Database searches were a bit more fun, but the problem is so embarrassingly parallel, that most labs ended up buying cheap PCs to build their own Linux farms; and with data production following Moore’s law, it wasn’t clear at all if this would ever become an interesting problem. To put it crudely, the only sexy way for biologists to burn CPU was molecular dynamics. “We will run CHARMM” would easily unlock the gates of heaven. I am actually curious to know how many billions worth of hardware investment were justified that way.
But everything changed by the turn of the century. Large Scale Genomics happened, fuelled by high throughput sequencing. Suddenly, subtle changes in the sequencing methods meant that biologists were producing sequences hand over fist. The growth of next generation sequencing output seemed impossible to curve - and it is still looking that way. It is not only that the density of sequencing machines is by-passing Moore's law, it is also that they are getting so cheap that their number is also growing exponentially. And when you stack exponentials, things happen...
For instance, all of a sudden, your new computer was proportionally handling less data than your previous one. This was a shock because I had become used to being able to do and run everything within my laptop. This little black rectangular box was significantly more powerful than Gin and Tonic, the two supercomputers rumored to have been gifted by the MI5 to the EBI when I was a student there. With the new data at hand, like genomic reads or RNASeq datasets, simple options were falling off the table one after the other. Fortunately, the CRG was rather fine storage-wise, but it was seriously lagging behind in terms of computation, and, as it happens, Amazon was beginning to offer online virtual machines. This was hard to resist. I once discussed this idea of exploring these possibilities with Anna Tramontano who told me, “Cedric, I have just the person you need”, and Paolo Di Tommaso happened... It started very simple, a master project I had pompously named Cloud-Coffee and whose goal was to benchmark T-Coffee on Amazon.
This is probably the only benchmark I ever did where rather than measuring sums-of-pairs or seconds, or more esoteric things, we simply measured something that would get everyone’s attention: cost in dollars. The game was to know how much it would cost to do all of our benchmarks over there. This was not an easy thing to do. The reporting tool on Amazon was a bit rough, and you had to keep reloading and quickly catch your dollar figures. The CRG was suspicious but supportive. Opening the account had been complicated because it had to be billed from a corporate card, and all these things, but it went well and we published the paper.
Then we got a bit bolder… Jia-Ming Chang was finishing his thesis in my lab. He was working on a very time intensive benchmarking system, where you had to compute zillion of alignments and measure tiny effects. Jia Ming had it all worked out, running like clockwork on our cluster, but Paolo and I managed to convince him that it would be cool to run all that on Amazon. Saying no was never Jia-Ming’s strongest skill and we knew that this geek at heart would be unable to resist the prospect. Then we started the computation and watched the dollars being transferred from my budget to Jeff Bezo’s account with very little happening. I mean very very little. Five thousand dollars later and with a few million three-leaf trees and one sequence-MSAs, we pulled the plug… Dependencies had killed us. The big fat instances we needed for the trees had spent their time and our money waiting for one another. I am not a real computer scientist but I know enough about parallelization to be aware that these mutual locks are the worst thing that can happen. Yet, without a proper centralized storage system, and with the inertia of popping up the instances, proper parallelization was beyond our reach on Amazon - at that time...
Paolo was hurt in his pride, I was hurt in my wallet, and Jia-Ming was knocked off his PhD deadline. We called it a day… I had another computer scientist in the lab, Maria Chatzou who had just joined us. Maria was about to take over from Jia-Ming’s work and she was understandably worried about managing massive amounts of computation. It is not that the kind of things we compute are very complicated, it is just that you have layers upon layers, that you need to keep connected. Like sequences that you turn into guide trees, that you may want to replicate, that you then turn into alignments and that you turn again into trees, and you do this hundreds of thousands of times. If you are an old guy like me, you script everything in Perl, pack it with “if file already there skip computation”, and you hope that tomorrow you will still be able to remember what you had in mind with the hash table named, euh... %H5. Python helps a bit, but still, when you start doing arrays of readouts, and arrays of arrays of arrays, everything becomes so nested that any tiny change turns everything into a new project. It is a bit like in those days when you would Xerox your PhD double sided, and the machine would jam, and, you know, it’s easy because you take these half printed sheets and put them back there, upside-down and face up, and… ahem, oups no, wrong side, etc…
Makefile would have been fine, but the computation of the dependency graph was a killer when using the GNU makefile, and at the time Snakemake did not exist, or we did not know about it. The main issue with makefile is that they build the tasks from the start till the end before starting. It means that makefile will not start any computation if it does not know for sure where it will end. Clearly not a Mediterranean concept… The alternative to makefile is called reactive programming. It is something that Paolo had started talking us into. The best example of reactive programming is piping in UNIX. Some data gets sent into some program, and things keep happening as long things keep flowing in. Nothing happens before and nothing happens after. The process down the pipe has no knowledge of how much it will process, and for how long. It simply knows that if a unit of data - arbitrarily defined as a data stream with specific properties - comes in, it has to munch it and spit as a result, another stream of data..
There is in front of the CRG, a giant sculpture representing a headless fish. It is known as the Golden Fish by Frank Gehry and was put in place for the 1992 Olympics. I cannot remember who once told this to me, but some story goes that the fish is headless as a tribute to Barcelona, that welcomes any one coming in without any second thought or prejudice. I never found anything written or else that would corroborate this nice story, but I quite like it. And in a way the headless fish is the precise symbol of a pipe or a Nextflow process. It actually defines the scaling capacity of an unprejudiced world.

Anyway, back to the lab. A few days after Paolo gave us a live demonstration of reactive programming deployed on Amazon, I had him and Maria banging on my door and screaming that we had to develop our own language pipeline using the reactive programming paradigm. I listened carefully to their justifications, thought deeply about it and emitted a profound , succinct and precise instruction: “NO”. As a consequence, Paolo, who had always been a master at reading between the lines, started immediately working on the first Nextflow prototype. This was about the end of 2012 and a few months later, on the 9th of April 2013, Paolo did put on GitHub the first public release: Nextflow 0.2.2. To be fair, I had said no because I thought developing a language would be beyond our capacity and I was afraid we would not be able to support it, but it was clear we needed something similar, and I quickly agreed that no matter how you turned it around this thing had to be a language. But being a language was not enough, it needed a special component, and that component, what makes it special, is the concept of reactive programming it is built upon.
Within my group, the success was immediate. The reason is simple. We had developed Nextflow for ourselves, because we needed it. My lab has always been smallish, about 10 people on average, and I have never had the resources to develop grand tools. I mean tools where you write the specs, turn them into documentation and do the implementation. Paolo understood very well that Nextflow had to be simple, and usable by our kind of people, that is to say, non professional computer scientists with a good grasp of scripting. He also knew that it had to be evolvable. This is exactly how Nextflow had been thought and this is the reason why so many people started using it beyond the CRG. It took 5 minutes to install, and even less to run your first pipeline. And what it was doing, the way it was doing it, was kind of obvious. Another important trick was that it could be used as a wrapper on existing pipelines, meaning that you would simply need to wrap some Nextflow tags around your old pipeline, whatever language it was written in, and Voilà! Recycling old pipelines was a non-negotiable thing for me, and I soon realised many of my colleagues were in the same situation. They had all these old albeit critical pipelines left behind by talented students whose many gifts did not include writing documentation.
But some bits were still missing, and most importantly the cloud thing was not yet solved. Our next step would be creating a cluster on the Cloud. This was not trivial because all these machines were not meant to share disk or memory. They were all somehow independent and Paolo kept digging out new innovative solutions equally ineffective: it was either working smoothly for a few minutes after hours of set-up, or elegantly crashing after a few minutes of set-up… It is around these days that Paolo brought Docker to our lives. For the record, he did this over a year before Google announced that Docker was a thing. This was all very confidential. In 2014, we published our first Docker paper. I remember being asked by the CRG faculty what had been my most influential paper of that year and mentioning this one for the highlights. My suggestion was politely ignored.
Now, I have to be fair to the CRG. Even though it is not entirely clear the institution understood the real aim of the project, they supported it without a flinch over many years. Between 2012 and 2017, I wrote every year in my annual report that we were working on a solution for the deployment of high throughput computational pipeline on the cloud, and all these years we had little to show for, but the support kept coming in and allowed me to pay Paolo so that he could work nearly full time on this. Given the track record and expertise of my lab, I can hardly think of any funding body that would have taken a chance on us. In fact we tried to raise some money a couple of times but never managed. This is just to say that core fundings is probably the most important and instrumental source of support to generate true innovation. Without the CRG core funding I would have little to show for. Grants are nice, but it has to look exciting, and you have to be lucky to be evaluated by people who understand why you are excited. And then you have to do stuff you may not believe in any more by the time you get the money. A lot has been written on why this is a poor system, and why it is a mathematical certainty that the best project will be the hardest to fund. Core funding is different, it is about hiring the right people and giving them freedom to do stuff for which they will be accountable. It is the closest we have to random funding, which, given the random nature of research, is probably the only way to go.
Now back to us and our results. Which results? Exactly... We had little to show, at least academically speaking. This is where Evan Floden steps in. Every year I teach a course in Bologna, at Rita Casadio and Pier Luigi Martelli’s master. And then my wife and I come back with two more kilograms (each) and a master student. 2015, was Evan’s turn. Even by the unusually high standards of this master you could tell that Evan was going to be special. He already had papers with Sean Eddy and the Rfam gang and was curious about absolutely everything. Every year the CRG runs an international competitive PhD call, and in his year Evan came out as the top ranked candidate, which allowed him to be funded by the La Caixa Foundation, like Maria had also managed just before him. His PhD had nothing to do with Nextflow, but he rapidly got hooked on it, especially the games with virtual machines and moving computation around places. If there is one thing I am proud of having achieved in my lab, it is fluidity across projects, with anyone feeling free to chip in any one else project. Of course you have to be strict on who owns what and so on, but having a collaborative rather than competitive environment makes life so much more pleasant on a daily basis - and so much easier...
Before Evan, Nextflow was a cool technical project that we planned to publish in some good solid no thrill journal. Then one evening the whole lab went out for pizza on Paral·lel, a large avenue of Barcelona, and the obvious place to discuss parallel processing... Nearly two years in the COVID era, I realize how strange such evocation may feel to many of us, but yes, having a pizza with your group used to be possible, and I hope it is again when these lines are being read. Anyway, we were having a pizza and Evan said, with his distinctive kiwee intonation, “BTW, I have been playing with Nextflow and Kalisto, did you know the results are different across machines ?”, The PhD supervisor in me immediately replied “Zis are RRandom seed geneRRators fluctuation Heavan”, “No” he replied “the results are reproducible on a given machine, but then they change depending on the operating system”. I was quite impressed, but he had saved the best bit for the end “but if you dockerize your computation, everything becomes reproducible again, even on AWS, the Amazon Web Service”. I was stoned, and suggested we looked at this first thing tomorrow. And he was entirely right. All things being rigorously equal: your data, your software, its version, etc, tiny variations were occurring across distributions. This was nothing huge, typically 1-2% variations, but if you do not expect them to occur, such variations are project killers. Imagine yourself trying to debug the pipeline of the paper you submitted 6 months ago, and being unable, as a start, to reproduce exactly your original result, simply because the cluster has been updated… Also, imagine that the same analysis of your exome points at two different target genes in two different hospitals…, and on and on… We had it immediately clear this was potentially a huge story, and it was time to write it up.
The Nextflow paper is not any paper, it is the first high impact paper that I managed to drive without being a simple hitch-hiker. The writing of this paper has probably been one of the most intense and exciting experiences of my academic life. We hear a lot about the DORA declaration on the assessment of science and all these things these days, and I am sure the people behind this mean well. In fact I agree with many of their positions and their implications, but not all of them. Especially when it comes to high impact factor journals. Writing papers for these journals requires developing a different set of writing skills. I understand many of the reasons why people are annoyed with these vanity papers, but I see it a different way. It takes about two to three times longer to write a paper for a 30+ IF journal, especially if you are not a native. You write these things with a razor. They have to be short, sharp, impactful and correct. It is as close as scientific writing can get to poetry - oups, here we go again on my linguistic obsessions... It was not the first time I was playing this game, but it was the first time I knew I had a real strong hand, and all of us were determined to pull it through, no matter how much pulling would be required.
What I am trying to say here is that you will only go for it if you think it is worth it, and this self evaluation is essential to provide Science with a sense of perspective. Everything we do is not equally relevant to the big picture. Some things carry more weight, and it is very important for any one new to the field, especially the students, to rapidly grasp the big picture. If all papers were published on a fully flat hierarchy, then it would be hard to really figure out what matters. Of course, social networks, and “likes” impression, and stuff could help, but this would be just re-creating high impact with an increased social component. Some will argue that the social component is more transparent than the editor's world. That may be true, but at the same time, the COVID-19 has just exposed how sensitive these things are to manipulation. If news were alleles, fake news would be the fittest - by far.
Now back to the Nextflow paper. It lists six authors but in reality, the main one is missing and not even acknowledged: Google Doc. I have no Google shares, but I humbly admit that without Google Doc the writing would never have been possible. This paper was 100% collective writing. We started with a rough draft and rewrote each and every sentence together. The beauty with a shared doc is that it happens in real time, everyone in front of their OWN computers (i.e. not sitting next to your supervisor keyboard!) in a room, or over the phone. You have editing fights. I had to write quite a few times “DON’T TOUCH THIS SENTENCE”. But the most rewarding thing is the possibility to tune it so that everyone reads the same thing. And everybody can contribute, even the most junior members of the team, who may find it harder to edit sentences or improve them. They can still argue that something does not make sense to them. It is not something to discuss, it is something to fix. I have now written 4 papers this way. Each of them was an amazingly intense process leading to what I consider masterpieces in my career along with some of the most pleasant group binding experiences you can generate.
Getting the paper accepted was still a long process. If I recall well, it took over 6 months, going back and forth. Pleading against rejection. I think we rewrote it almost from scratch a couple of times and I saved a total of 27 versions with countless edits in between. But eventually we made it through and the resulting sense of collective victory was overwhelming. When it happened, Nextflow already had its own life supported by a vibrant community of enthusiasts for whom Paolo was acting as a grand master.
It had been clear from the start that Nextflow was an engineering project and that its future was in between academia and industry. I was therefore not totally surprised when Maria and Pablo Prieto, two of my PhD students announced that hey wanted to incorporate a company, named Lifebit, making use of Nextflow, but when Paolo and Evan did the same with Seqera Labs I realized this was becoming a trend. Both companies are doing amazingly well these days, and Seqera Labs, have just successfully launched Nextflow Tower, a powerful computation controller. They have also just raised $5.5M while securing three grants from the Chan and Zukerberg initiative. LifeBit is just as successful and its sharp focus on AI led it to being recently awarded a major genomics contract in Honk Kong.
Those who know me are well aware that my core interests have always been much more academic than business oriented, but I am immensely proud of our work. Thanks to our collective work, a very technical breakthrough whose normal fate could have been to become an obscure addendum at the bottom of a mat and methods section has received the light it deserved. And this exposure has contributed towards reproducibility.
Standardizing pipelines is not only about efficiency and applications. It is also about readability. Soon, all of our medical data will be processed by such pipelines. Based on your data, they will spit a number, sometimes this number will mean you are eligible for the miracle drug everyone is talking about, but at other time this same number say that the drug is unlikely to work on you and that social security should rather spend its limited resources giving it to someone else. You will then be provided with an older less effective treatment. Too often, this will be the difference between life and death.
If this happens to you, the sense of unfairness is probably unbearable. Like being punished twice while innocent. And if you do not trust the source that made this decision, the sense of unfairness will turn into boiling anger. It is only with sufficient transparency that we will engage our fellow citizens in accepting that the analyses deciding on their fate are being fair to them. Open code when it comes to genomic analysis is not only a scientific issue, it is a democratic issue. And to be of any use, open code has to be readable by people we trust, that is to say, as many people as possible. And to achieve this, the code must be readable.
This is where Phil Ewels steps in. Phil was one of the first adopters of Nextflow, at SciLifeLab and his philosophy was that of providing the whole world with good trustworthy tools. With a group of enthusiasts he created one of the most vibrant Nextflow community. The NF-Core collection of curated pipelines they put together is one of the reasons so much has been achieved with Nextflow. If I had to pick one major success, it would be the use of Nextflow in CLIMB-Covid. These people have created in no time the most sophisticated ever system for COVID data processing and their software has analyzed about a quarter of all COVID genomics data produced these last two years. COVID is still there, but in the West, money and vaccination are turning it into a manageable curse. Vaccines were part of the solution, but they were not enough. I would argue that data processing is just as important as vaccines, and in fact, this is just what the new variants are telling us: keep processing data. Well, here we go and the fact that these people found Nextflow a useful tool justifies all of our efforts.
Another thing that I am really happy about, as a PI and a scientist, is that we could achieve this without having to change the lab direction. Nextflow was an incidental support of the work on sequence analysis that I consider central to my academic interests. Being able to contribute to such a technical project without having to change direction was just as rewarding to me as the work I did in sociology with Lausanne university, many years ago - but that’s for another blog post. We hear a lot of the word interdisciplinarity these days. To be honest, I can hardly think of a concept that has been so worn off and misused. Whenever I hear it coming from the top of the hierarchy, I just switch off, as it usually means truck loads of money poured on the wrong spot, with instrumentalized scientists pressured into claiming about their interdisciplinarity, with tattoos and piercings. It never works, and the reason is simple: purpose built interdisciplinary work is usually lame for any of the disciplines it is made of: it falls between the cracks because nobody finds it truly exciting. On the contrary, incidental interdisciplinary work cannot fail. It comes out of chance and necessity. I was not especially interested in IT. In fact, I don’t even like computers, I like algorithms and the closer I get to hardware and its plumbing, the more I feel that I am back to my teen years, having to tweak my moped again and again. Something I was never good at. But I needed Nextflow, my lab needed it and I had no choice but to hire the best IT person I could find and get to explore the IT world with them. I got very lucky to find similarly minded people in my lab. I would re-do the entire journey any time.